Speaker: Roger Hoover, Engineer, Confluent
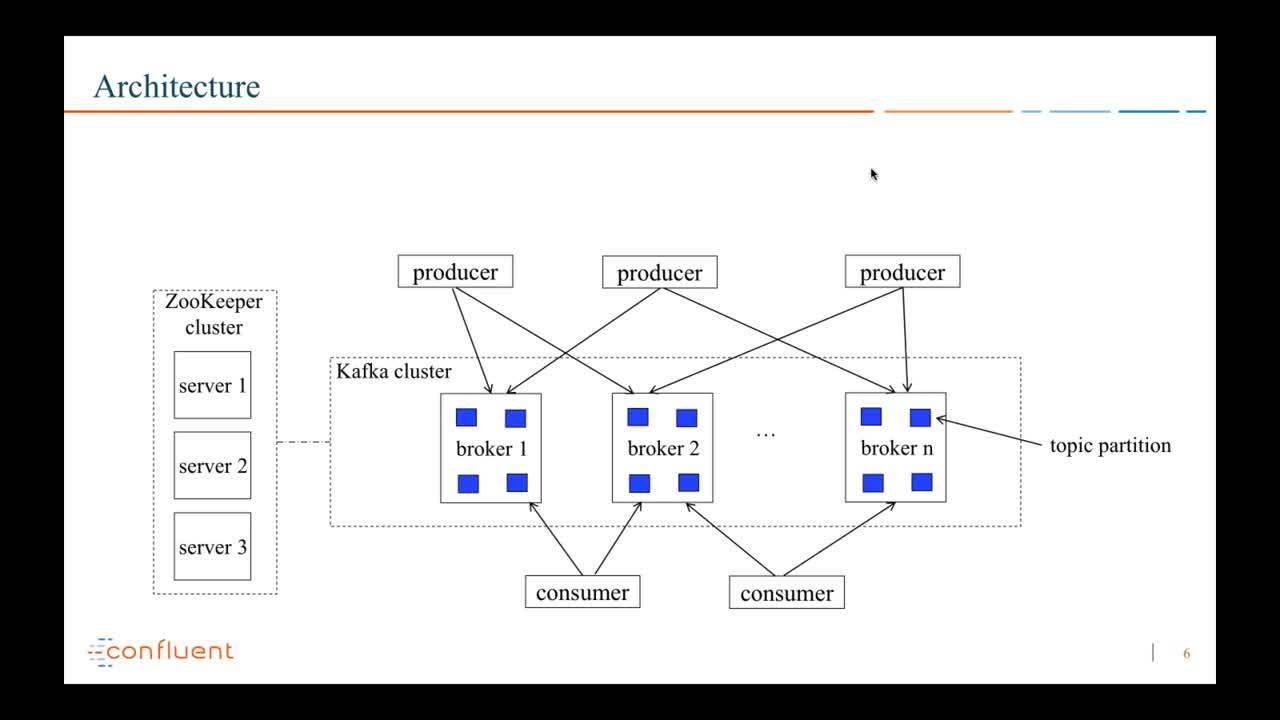
The previous talks in this series cover components of the Apache Kafka® ecosystem and stream processing in general. This talk will focus on how to integrate all these components into an enterprise environment and what things you need to consider as you move into production.
We will touch on the following topics:
- Patterns for integrating with existing data systems and applications
- Metadata management at enterprise scale
- Tradeoffs in performance, cost, availability and fault tolerance
- Choosing which cross-datacenter replication patterns fit with your application
- Considerations for operating Kafka-based data pipelines in production
This is part 6 out of 6 of the Apache Kafka: Online Talk Series.