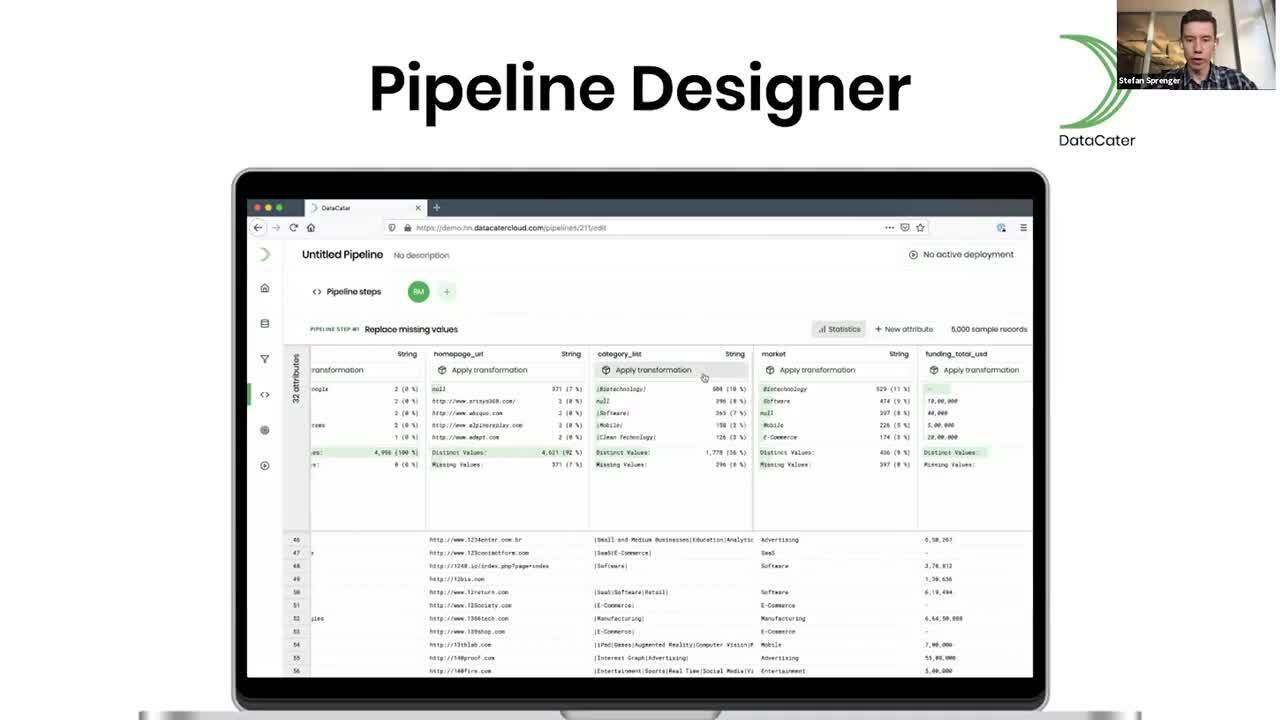
DataCater allows data experts to prepare data for analytics and data
science applications. DataCater provides the Pipeline Designer as an
interactive means to building streaming data pipelines without code
(Python UDFs are supported though ;-)) and makes sure that prepared data are always in sync with raw data.
In this talk, we’ll have a look under the hood of DataCater and explore
how it combines multiple components from the Kafka ecosystem, e.g.,
Kafka Connect, and Kafka Streams, to fully automate data preparation for analytics. Using an example, we’ll investigate how DataCater turns a
data pipeline built with the Pipeline Designer into executable code
deployed as a container.
Slides:
https://www.slideshare.net/ConfluentInc/data-preparation-without-writing-a-single-line-of-code/ConfluentInc/data-preparation-without-writing-a-single-line-of-code