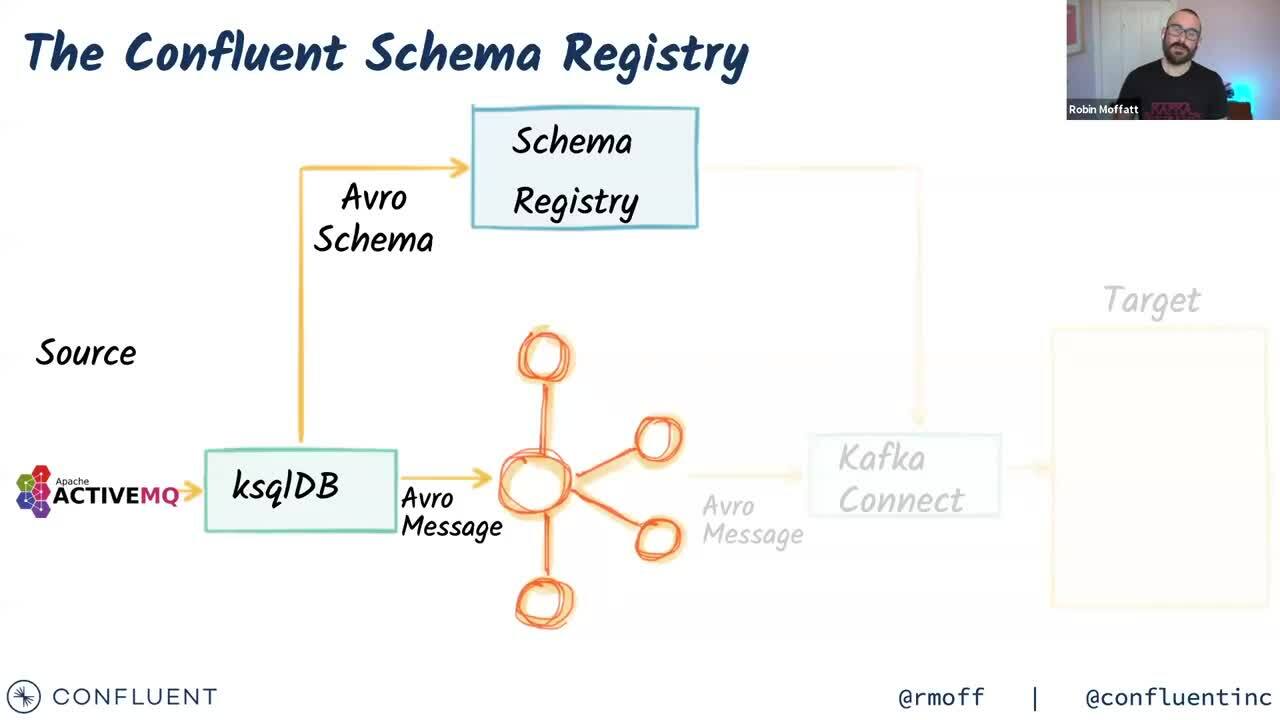
As data engineers, we frequently need to build scalable systems working with data from a variety of sources and with various ingest rates, sizes, and formats. This talk takes an in-depth look at how Apache Kafka can be used to provide a common platform on which to build data infrastructure driving both real-time analytics as well as event-driven applications. Using a public feed of railway data it will show how to ingest data from message queues such as ActiveMQ with Kafka Connect, as well as from static sources such as S3 and REST endpoints. We’ll then see how to wrangle the data into a form useful for streaming to analytics in tools such as Elasticsearch and Neo4j. If you’re wondering how to build your next scalable data platform, how to reconcile the impedance mismatch between stream and batch, and how to wrangle streams of data—this talk is for you!
Slides:
https://talks.rmoff.net/h6aUqU/on-track-with-apache-kafka-building-a-streaming-etl-solution-with-rail-data